
Most teams do not lose because they cannot write a proposal. They lose because they spend days chasing a competition they were never likely to win. If a fresh RFP drops and your first move is to staff solution and pricing before pressure-testing risk signals, you are betting labor on hope.
This guide gives you a concrete, repeatable way to screen for influence risk in about 20 minutes, then decide whether to commit capture resources. The goal is not conspiracy hunting. The goal is disciplined bid qualification under time pressure.
TL;DR
Use a 9-flag influence-risk score before staffing capture. If the score is high, escalate or no-bid early. If the score is low, pursue with controls and move to hard-gate checks in Sections L and M.
The most expensive mistake is betting on a competition that was never open
The most expensive no-bid mistake is not a weak first draft. It is pursuing a competition that was never truly open while a better-fit opportunity sits untouched. You can recover from writing. You do not recover the week your team burned on a low-probability bid.
Serious capture teams run a quick influence-risk screen in about 20 minutes before they assign solution, pricing, or proposal labor.
Fresh RFP dropped. What would you do?
It is Tuesday morning. A fresh federal RFP drops in your target account. Technical scope looks like a fit. Leadership wants an answer by tomorrow on whether to staff pursuit.
What do you do first?
Option A
Assign solution and pricing resources immediately because scope fit looks strong.
Option B
Label concerns as paranoia, skip a structured screen, and move straight into proposal outline work.
Option C
Run a 20-minute influence-risk screen first, score confidence, then decide whether to staff capture.
Correction: Option C wins. A and B feel fast, but they hide risk until expensive work has already started.
Why "wired" usually means pattern, not proof
In capture, "wired" is shorthand for influence risk. It is not a verdict. A single odd requirement can be legitimate. What matters is whether multiple independent signals stack the same way and whether you can cite them in the solicitation, amendments, and Q&A.
This article gives you a repeatable scorecard so suspicion turns into evidence and a go/no-go call, not hallway gossip.
The 9 red flags that should change your go/no-go decision
Use this list as a screening tool, not a legal conclusion. One flag alone does not prove an RFP is wired. Stacked signals should change how aggressively you pursue.
Over-specific past performance profile
Requirements are framed so narrowly that they mirror one incumbent footprint (contract size, exact agency niche, unusual timeline overlap) with little room for adjacent relevance.
Scope language mirroring one known incumbent playbook
Performance approach appears drafted around one existing environment, stack, or transition path with minimal rationale for alternatives.
Qualification gates mismatched to contract risk
Certifications, staffing profiles, or facility requirements appear heavier than what the work objectively demands at this stage.
Compressed timeline with weak market response window
Turnaround windows are unusually short relative to proposal complexity, limiting entrants who were not already pre-positioned.
Amendments that narrow competition late
Late amendment changes tighten eligibility or proposal structure in ways that reduce viable offerors instead of clarifying requirements.
Evaluation weighting that undercuts true best value
Section M weighting appears misaligned with mission outcomes, placing unusual emphasis on factors that favor one profile.
Site visit or Q&A behavior that limits broad participation
Responses are vague, selectively scoped, or delayed in ways that leave critical interpretation gaps unresolved for the broader field.
Staffing and key-person demands that imply prior knowledge
Named-role requirements combine niche domain history and immediate availability in a pattern that strongly favors incumbency.
Data rights and transition clauses favoring the existing environment
Clauses around data access, tool continuity, and transition assumptions create high switching friction without clear mission justification.
20-Minute Influence-Risk Screen (Step-by-Step)
Scoring model
- Score each flag 0-2: 0 absent, 1 possible signal, 2 strong signal with citation.
- 0-5: pursue with normal controls.
- 6-11: conditional pursue, leadership review required.
- 12+: default no-bid unless strategic exception is documented.
Create a one-page output with (1) total score, (2) evidence table with citations, (3) go/no-go recommendation, and (4) escalation notes.
AI Prompts to Triage Faster (With Citations)
AI can accelerate extraction and comparison, but it cannot replace source verification. Use it as a first-pass analyst. Every output row needs a citation you can find in the PDF.
Prompt starter 1: incumbent-favoring language scan
Prompt starter 2: unusually specific experience or certification gates
Prompt starter 3: amendment drift and narrowing behavior
Prompt starter 4: protest-risk indicators (citation only)
After you build an evidence table, you can paste it back into your model and ask for 0-2 scores per flag with one cited sentence each. Treat that output as a draft until a human confirms every cite against the PDF.
Common AI failure modes: false confidence, missing amendment precedence, lack of procurement context, and conclusions without cites. Force citations, run a skeptic pass, and keep a human in the final decision loop.
What You Must Verify Before Calling No-Bid
Before you call no-bid, verify every high-score signal on the source solicitation and amendment PDFs, plus official Q&A. This framework supports bid decisions, not legal conclusions. It is bid-risk triage, not legal advice and not a protest determination.
When Manual Review Stops Scaling
Even strong teams drift when multiple RFPs drop, assumptions carry across pursuits, and handoffs lose context. The method is sound. Consistency under amendment churn and volume is the problem.
The orchestration layer
askaGOAT operationalizes this same screen across the full package
If you care about this discipline but do not want it to depend on one person and one late-night spreadsheet, upload the full package to askaGOAT. Get Hoofnote-style triage with repeatable evidence extraction and faster go/no-go clarity.
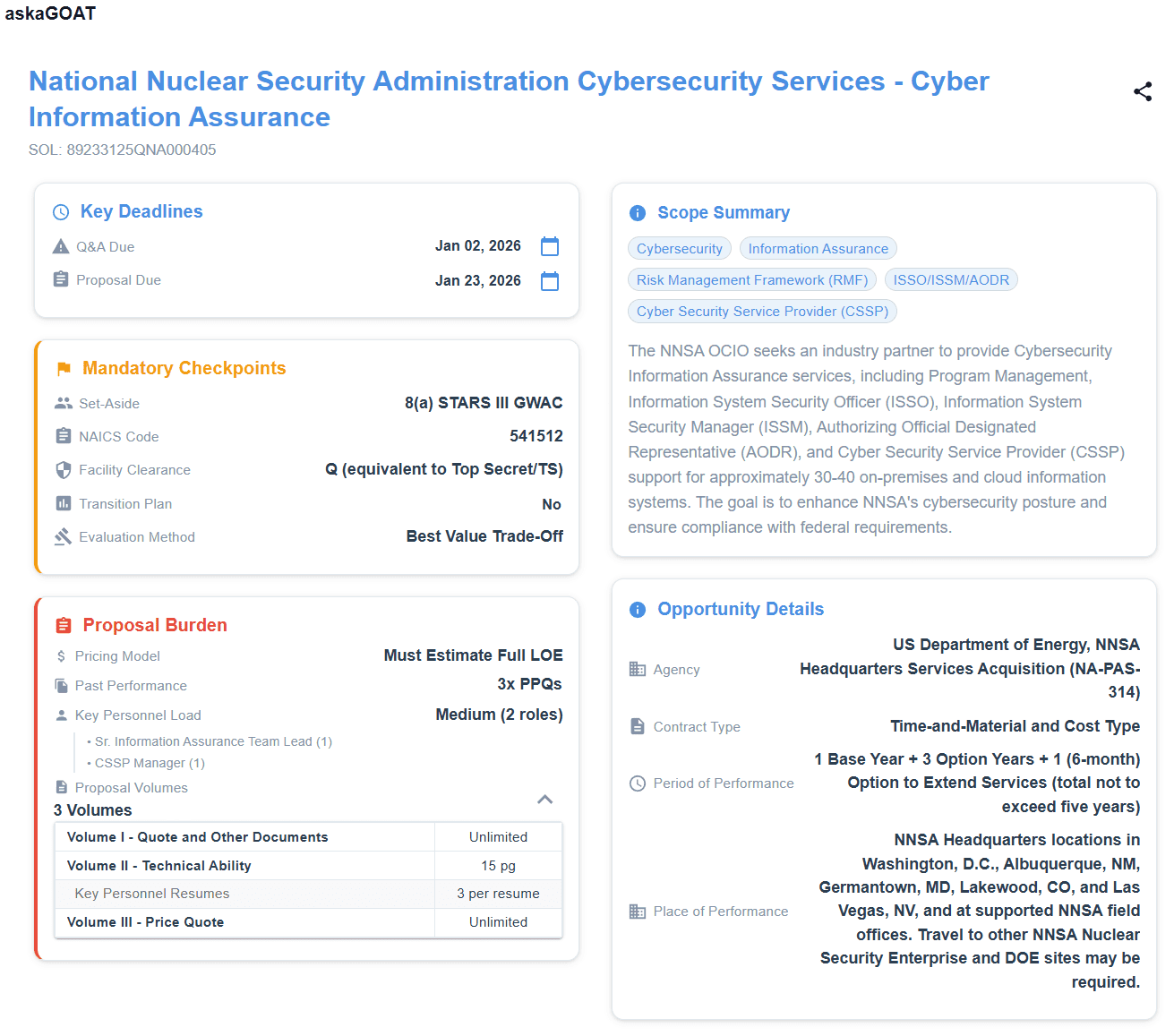
One page, one score, one decision path before your team burns proposal hours.
Try It FreeNo credit card necessary.
Next steps for your team
After this screen, run your normal hard-gate check in mandatory requirements review, then size effort with capture workload discipline.
If your pipeline quality is the root issue, tighten top-of-funnel sourcing with this SAM.gov automation playbook.
Protect capture bandwidth before you commit proposal labor
Use askaGOAT to surface risk signals, hard gates, and workload early so your team spends time on bids you can actually win.
Start Your Free TrialNo credit card necessary.