Here is the uncomfortable sentence: evaluators do not score your “great idea.” They score coverage against Section M’s factor structure. Misalignment is not a stylistic problem. It is a scoring miss. The win strategy is M-first, not story-first.
If you already reviewed Section L for submission rules, good. Section M answers a different question: what proof earns points, and what eliminates you before that proof is read.
TL;DR
Parse Section M into factors, subfactors, pass/fail gates, and rating definitions. Build your response outline from M, then map evidence. Use AI to draft the structured outline; verify rating methods and ties on the PDF.
The capture meeting: what would you do?
The pursuit meeting is in 48 hours. Ops wants to highlight innovation. BD thinks price drives the award. Another voice insists past performance is “the real discriminator.” Nobody has Section M on screen. Sound familiar?
What do you do right now?
Option A: Win themes from Section C
Draft themes from the SOW and technical challenges. Lead with your strongest engineering story.
Option B: Parse Section M into an evidence map
Extract factors, subfactors, gates, and rating method. Build the proposal outline from M, then assign proof by subfactor.
Option C: Read M once and highlight
Mark “important parts” in yellow and continue with the outline you already like.
The correction: Option B wins. Option A optimizes the wrong game when M weights something else or applies pass/fail gates you never addressed. Option C keeps ambiguity alive: deficiency definitions, order of importance, and unstated ties between technical factors and price stay fuzzy until it is too late.
The industry-standard Section M workflow
Strong capture teams read M the way a source selection panel does: what gets eliminated first, then what gets rated, then how ratings combine. They separate “compliant in Section L” from “scores under Section M.” Those are different jobs.
Pain this workflow avoids: win strategy mismatch (great tech story, wrong weights), structure mismatch (beautiful narrative that does not land under the factors), and amendment shifts that silently reorder importance.
Workflow at a glance
- Identify the stated evaluation scheme (examples: LPTA, best value tradeoff, etc.). Always verify the solicitation’s labels.
- Extract pass/fail, thresholds, or unacceptable language before you tune narrative.
- Build a response outline that mirrors M’s factor and subfactor headings.
- Pull adjectival rating definitions (or the solicitation’s equivalent) into a quick reference.
- Map proof artifacts (past performance, staffing, management approach) to subfactors, not generic volumes.
- Re-run when amendments touch M. One Mod can reorder the entire pursuit.
AI to the rescue: techniques and prompt starters
Use AI to force structure. The failure mode you are avoiding is a cohesive essay that never lands where scoring happens.
Techniques:
- Role prompt: “You are a contracting officer support specialist drafting an outline from Section M only.”
- Structured output only: reject prose summaries until you have headings aligned to M.
- Crosswalk pass: “Flag contradictions between Section M and Section L submission requirements” (for example, required evidence named in M but not listed as a volume in L).
Prompt starter 1: M to outline
Prompt starter 2: rating definitions
Prompt starter 3: gate extraction
Prompt starter 4: contradiction sweep
Common AI failure modes (Section M): flattening pass/fail into narrative, inventing numeric weights when the solicitation uses relative order, and “helpfully” merging factors. Fix with mandatory cites and structured outputs.
Verification (non-negotiable)
A human confirms the rating method, any tie-breaking order, and whether price or past performance truly drives the tradeoff as written. Models summarize; humans certify what the solicitation says.
Why outlines still fracture without a system
Even with perfect prompts, teams juggle three highlighted PDFs after Mod 04. Writers anchor on different versions. The gap is one canonical evaluation map tied to the living package.
Unique mechanism
askaGOAT keeps Section M tied to the whole solicitation
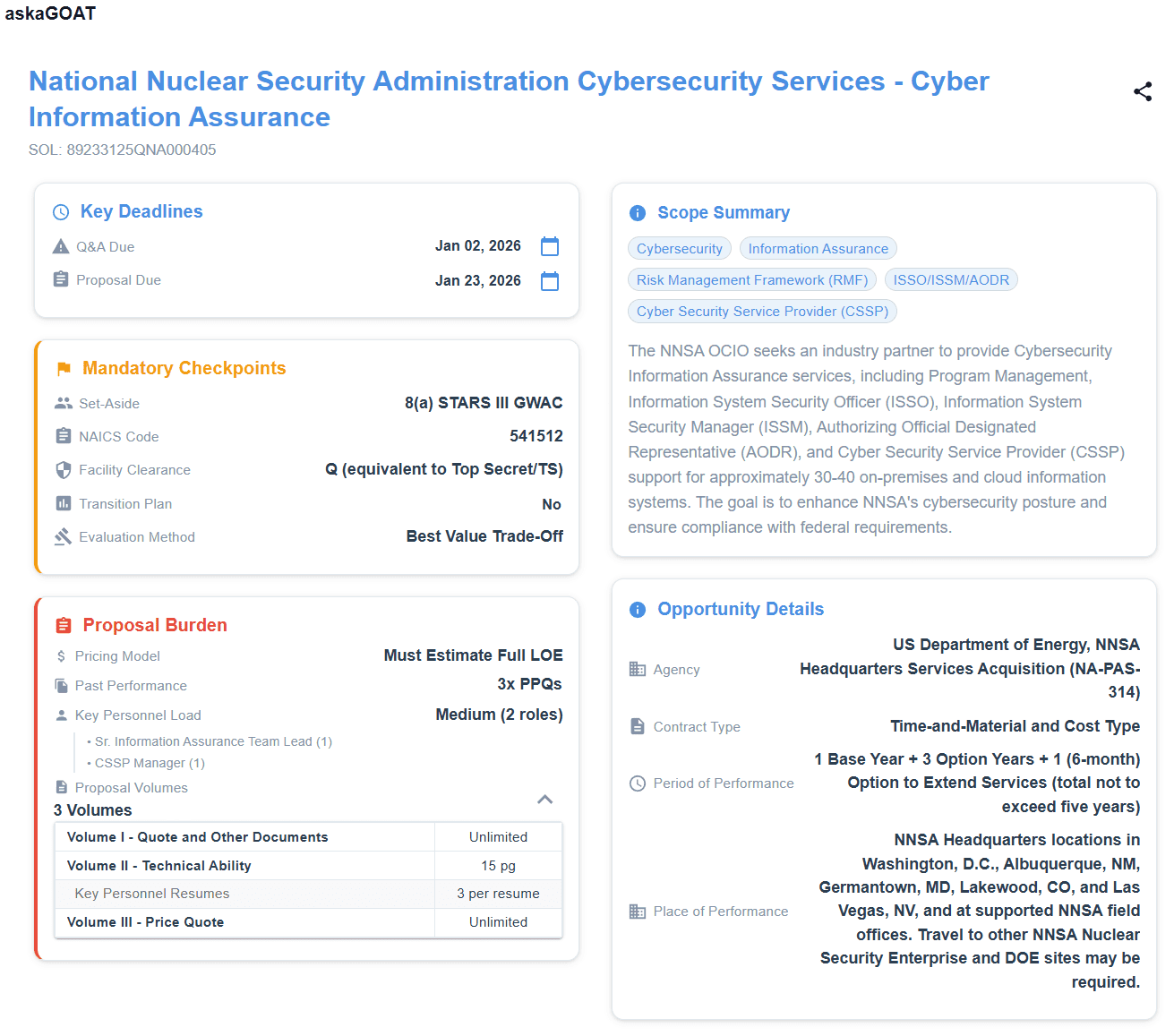
askaGOAT ingests the RFP package so evaluation structure, dates, and mandatory checkpoints stay aligned through amendments. Same discipline as your prompts, without the Friday-night version drift.
No credit card necessary.
Next in this series
After instructions and scoring, force-multiply your story with defensible references: federal RFP past performance review.
Frequently asked questions
What is federal RFP Section M for?
Section M states evaluation factors, subfactors, and the basis for award. It tells you how evaluators score proposals and where pass/fail or minimum thresholds live before anyone reads your technical approach for style points.
What are pass/fail gates in Section M?
These are elimination rules, minimum acceptables, or defined ratings that remove an offeror from consideration if unmet. Extract them as explicit rows with controlling quotes, not as narrative “themes.”
How should Section M inform your outline?
Mirror evaluation factors and subfactors exactly in your outline headings so writers map evidence to how the government scores. Use structured prompts that forbid inventing weights or merging factors not stated in Section M.
Why cross-check Section M against Section L?
Conflicts appear when Section M asks for proof that Section L does not allow you to submit in a given volume, or when submission rules make an evaluation requirement impractical. Surface those conflicts early with citations.
Turn Section M into repeatable triage
Start a free trial and upload a solicitation. See evaluation context alongside submission rules before your team commits the proposal outline.
Start Your Free TrialNo credit card necessary.